
本文已获得原作者(Svyatoslav Kryukov、Travis Turner)和 Evil Martians 授权许可进行翻译。原文讲述了在进行 Rails API 开发时,一种基于 OpenAPI 标准的文档优先方案是如何产生,又是如何实践的。
- 原文链接:Let there be docs! A documentation-first approach to Rails API development
- 作者:Svyatoslav Kryukov、Travis Turner
- 站点:Evil Martians ——位于纽约和俄罗斯的 Ruby on Rails 开发者博客。 它发布了许多优秀的文章,并且是不少 gem 的赞助商。
【正文如下】
引言
在本文中,我们将研究 API 文档的方案,并说明为什么文档优先的方案有益。此外,我们不仅会介绍一个新的 Ruby gem,对于那些准备走这条路的人来说,这将是一个启示,你可以继续阅读实用的技巧和建议。
起初,仓颉造字,鬼神夜哭。
而 Roy Fielding 创造了 REST。
尽管存在更高级和结构化的标准,如 GraphQL 和 gRPC,但我们仍然经常选择旧的 REST。REST的吸引力在于它的简单性和它提供的开发自由度。
然而,熟悉 REST 的人很清楚它带来的主要挑战:文档。
然而,有效的文档至关重要,因为它是客户和团队成员与 API 交互的协作基石和权威指南。
因此,一个紧迫的问题出现了:记录 API 的最有效方案是什么?让我们先来看看几种。
Approaches to API documentation
手动编写文档是一种简单的方案,开发人员只需在代码完成后描述实现即可。
可能采用 Notion 中的页面或 README 文件中的部分章节——这并不重要,因为生成的文档经常过时,并且很容易与实现本身不同步。
但归根结底,这种方法真的很无聊!
也许我们能以某种方式从实现代码中生成文档?代码优先方案涉及使用 DSL 直接从 API Controller 来生成文档。下面是 grape-swagger DSL 的一个资源示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
class Petstore < Grape::API
desc "Add a new pet to the store", tags: ["Pet"],
http_codes: [
{code: 201, message: "Pet added", model: Api::Entities::Pets}
]
params do
requires :pet, type: Hash do
requires :name, type: String,
documentation: { example: "doggie" }
requires :photo_urls, type: Array[String],
documentation: { example: ["https://example.com/img.json"] }
optional :tags, type: Array[String],
documentation: { example: ["dogs"] }
end
end
post do
spline = Spline.create(spline_params)
present spline, with: Entities::Splines
end
end
有了 grape-swagger DSL,我们只需调用 add_swagger_documentation 帮助方法即可始终将最新的文档添加到我们的应用程序中。
这种方案可能看起来很有前途,但在实践中,仍然存在一些缺点:
- 文档依旧只有在代码实现后才准备好
- 我们的 Controller 现在充斥着神奇的、充满元数据的 DSL
- 最后,没有测试来断言生成的文档是有效的
一个显而易见的解决方案是将这些 DSL 从 Controller 转移到测试中。
因此,测试优先方案就来了。它改变了开发流程,现在我们可以先编写测试,然后用一些 DSL 来生成文档。
下面是 RSpec 与 rswag DSL 的示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
require "swagger_helper"
describe "Petstore API" do
path "/pets" do
post "Creates a pet" do
tags "Pet"
produces "application/json"
request_body_example value: {name: "doggie", photo_urls: []}, name: "pet", summary: "Pet"
response "200", "Pet added" do
schema type: :object,
required: ["name", "photo_urls"],
properties: {
name: {type: :string},
photo_urls: {type: :array, items: {type: :string}},
tags: {type: :array, items: {type: :string}},
}
run_test!
end
end
end
end
我们现在可以确保,只要我们的测试准确无误,则文档也将准确无误。
然而,尽管文档在代码实现之前就已经准备好了,但仍然只有在编写测试后才能阅读。代码优先和测试优先方案的主要问题是开发者可能会忽略生成的文档。
通常,这种生成的文档不清晰,包含函数名称而不是描述,省略了属性值,以及其他各种疏忽。生成的文档被视为另一个人工产物,而这本应是我们要更关注的。
The documentation-first approach
由此,我们来到了文档优先的方案。这会将开发者的注意力转到在开始编写代码之前就制作详细的文档。
虽然我们称它为“文档优先”,但实际上将其称为“纲要优先”甚至“规范优先”更适用于这种方案,因为生成的文档不仅仅是一些文档,更是一个全面的规范。
无论如何,这开辟了许多可能性:开发者不仅可以生成文档,还可以根据规范测试应用程序,验证传入的请求,使用模拟和代码生成器,等等。
使用这种方案还可以增强开发的工作流:开发者可以首先起草规范,与团队讨论,并确保 API 满足所有必要的需求。
接下来,他们可以添加测试以确认规范是否按预期工作,最后再实现 API。(后两个步骤可以交换,具体取决于你对 TDD 方法论的偏好。)
让我们总结一下文档优先方案:
- 它不使用任何 DSL 来生成文档供团队中的任何人阅读和编辑。
- 此外,文档在实现或测试之前就已准备就绪了,因此开发者可以更早地获得反馈。
- 最后,文档本身就是规范。
文档优先方案是 API 开发中最有效和利于协作的方法。
唯一的缺点是,对于某些团队来说,文档优先的方案可能需要改变工作流程。
现在,让我们看看这种方案的实际效果。
Documentation-first: an illustrated example
第一步是选择规范格式,虽然有很多选项,但 OpenAPI 是最受欢迎的一种,可以说被认为是事实上的标准。
要了解有关 OpenAPI 的更多信息,请考虑查看 Petstore API。这是使用 OpenAPI 且有友好文档的 API 的一个很好范例,虽然它通常用于演示和示例,但对于本文目的来说,它有点过于复杂了。因此,让我们看一下“Noah’s Ark【诺亚方舟】 API”。
场景:假设我们已经实现了一些功能,比如一个简单的 CRUD,用于处理方舟上存在(或不存在)的动物——并且我们已经收到了来自用户的积极回应!
因此,备受鼓舞的利益相关者——方舟的首席执行官——向我们提出了一个新的功能需求:实现摘要功能。这个要求有些含糊不清,不幸的是,首席执行官已被其他任务淹没了,所以无法立即回答我们的问题。
这意味着我们需要先自己想出一些东西。
我怀疑方舟的首席执行官想要创建一个类似于 X/Twitter 的那种摘要!这里,动物们可以在网上进行口头混战,而不是在方舟本身的现实生活中。
我们将此视为一个合理的假设,因为当然,这段时间里,社交网络就像雨后春笋般涌现。因此,让我们用 OpenAPI 来描述这个功能!
OpenAPI
让我们从最小且有效的 OpenAPI 文档开始:
1
2
3
4
5
6
7
openapi: 3.1.0
info:
title: Noah's Ark API
version: 1.0.0
paths: {}
不幸的是,解释 OpenAPI 的每个关键字和功能都需要很长时间,这也不是本文的重点,所以让我们跳过这点直接深入了解它带来的外观和感觉吧。
接下来,我们将为新的摘要功能添加三个请求:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
paths:
"/feed":
get:
summary: Get a list of messages
operationId: getFeedMessages
post:
summary: Add a new message to the feed
operationId: postFeedMessage
"/feed/{message_id}":
get:
summary: Get a message by id
operationId: getFeedMessage
以这种方式描述请求是个好主意,从上到下,并在每个后续步骤中添加更多详细信息。
现在,让我们放大一条特定的路径:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
paths:
"/feed":
get:
summary: Get updates about the animals
operationId: getAnimalsFeed
responses:
"200":
description: OK
content:
application/json:
schema:
type: array
items:
type: object
required: [id, animal_id, message]
properties:
id:
type: integer
format: int64
animal_id:
type: integer
format: int64
message:
type: string
"403":
description: Forbidden
在此步骤中,我们仅添加了成功响应的描述。请注意关键字 schema ,以及 OpenAPI 在其内部使用不同的规范这一事实:JSON Schema。这甚至可以用于验证 OpenAPI 之外的 JSON,它是一个很好的工具,可读性好且易于理解,但有点冗长。为了解决这个问题,我们可以使用引用:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
paths:
"/feed":
get:
summary: Get updates about the animals
operationId: getAnimalsFeed
responses:
"200":
description: OK
content:
application/json:
schema:
type: array
items:
$ref: "#/components/schemas/FeedItem"
components:
schemas:
FeedItem:
type: object
required: [id, animal_id, message]
properties: #...
这里,我们在本文档中引用了一个本地组件,但也可以引用外部文件或 OpenAPI 描述,这样我们就可以避免处理数千行的代码文件。
接下来,我们可以迭代这个规范,添加越来越多的关键字和功能,直到我们对结果感到满意。一旦我们完成了规范,就可以利用 OpenAPI 生态系统了。
OpenAPI Ecosystem
用 YAML 编写规范可能看起来很痛苦(一开始确实如此),所以这里有几种方法可以让开发者的生活不那么悲惨:
- Swagger Editor:一个基于 Web 的应用程序,例如,可以嵌入到开发环境的应用中。
- Redocly VSCode Extension:一个来自 Redocly 的 Visual Studio Code 扩展。
两者都可以辅助开发时自动提示、进行预览等等。
毫无疑问,作为一名专业的 Ruby 开发者,你每天都在使用 RuboCop,但你会 lint 检验 OpenAPI 文档吗?如果没有,那你应该做。而 Spectral 就是一个可选方式。即使你使用代码优先或测试优先的方案,将 Spectral 添加到工作流程中也会提升你的文档:
1
2
3
4
5
6
7
8
❯ spectral lint docs/openapi.yml
/noahs_ark/docs/openapi.yml
3:6 warning info-contact Info object must have "contact" object. info
16:5 warning tag-description Tag object must have "description". tags[1]
26:9 warning operation-operationId Operation must have "operationId". paths./animals.get
✖ 3 problems (0 errors, 3 warnings, 0 infos, 0 hints)
有关更多规则和示例,请参阅 Spectral rulesets.
准备好 OpenAPI 规范后,前端团队就可以使用 mock 服务器(如 Prism)开始实现他们的功能部分:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
❯ prism mock docs/openapi.yml
[1:49:35 PM] › [CLI] ▶ start Prism is listening on http://127.0.0.1:4010
[1:49:47 PM] › [HTTP SERVER] get /animals ℹ info Request received
[1:49:48 PM] › [NEGOTIATOR] ℹ info Request contains an accept header: */*
[1:49:48 PM] › [VALIDATOR] ✔ success The request passed the validation rules. Looking for the best response
[1:49:48 PM] › [NEGOTIATOR] ✔ success Found a compatible content for */*
[1:49:48 PM] › [NEGOTIATOR] ✔ success Responding with the requested status code 200
[1:49:48 PM] › [NEGOTIATOR] ℹ info > Responding with "200"
❯ curl http://127.0.0.1:4010/animals
[{"id":0,"name":"Polkan","species":"dog","sex":"male"}]
❯ curl -X POST http://127.0.0.1:4010/animals \
-H "Content-Type: application/json" \
-d '{"name":"Polkan","species":"dog","sex":"male"}'
{"id":0,"name":"Polkan","species":"dog","sex":"male"}
此外,前端团队可以使用 openapi-typescript 来增强类型安全性,它将 OpenAPI 规范转换为 TypeScript 类型:
1
2
> npx openapi-typescript docs/openapi.yml -o app/javascript/api/schema.d.ts
🚀 docs/openapi.yml → app/javascript/api/schema.d.ts [39ms]
而 openapi-fetch 库更进一步,允许基于 OpenAPI 规范动态生成 API 客户端。这样就无需手动编写 API 客户端代码,从而节省了时间并减少了开发资源开销:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
import createClient from "openapi-fetch";
import type { paths } from "./api"; // generated by openapi-typescript
const client = createClient<paths>({ baseUrl: "https://noahs.ark" });
const {data, error} = await client.GET("/animals/{animal_id}", {
params: {
path: { animal_id: "0" },
},
});
await client.POST("/animals", {
body: {
name: "Sea-Tac Airport Facebook YouTube Instagram Snapchat",
species: "cat",
sex: "female",
},
});
这种级别的自动化极大简化了开发工作流程,使前端团队能够专注于构建健壮的类型安全应用,而不必操心 API 交互的底层样板代码。
你可以在这里找到更多 OpenAPI 工具:https://openapi.tools.
最后,整个团队都可以利用漂亮的文档生成器,如 Swagger UI, Elements, Redoc:
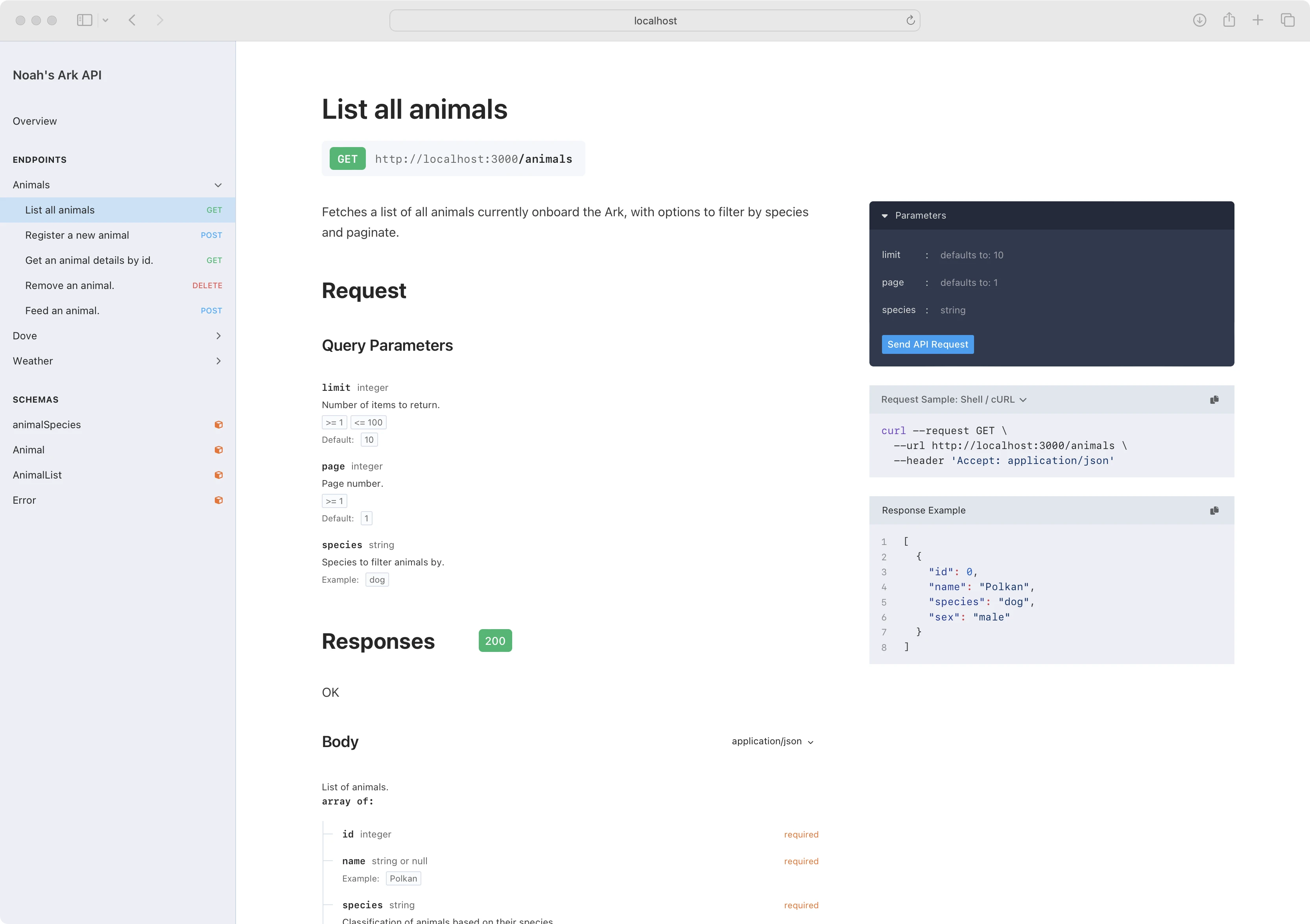
Collaboration
但最重要的工具是协作,团队内部的前端、分析、利益相关者等之间的协作。通过文档优先的方案,就可以轻松地与他们讨论和改进功能。
现在,当我们编辑、检验和渲染文档后,把它展示给方舟的首席执行官吧。
你们的工作很棒,但我想的是投喂动物,而不是动物的摘要……【译者注:英文里这里用的是 feed 这个词,在软件领域也有“摘要”的意思,所以造成上面理解的歧义】
哎呀,看来我们误解了需求,说实话,这种误解在软件开发中一直都在发生。但是,我们改用文档优先的方案不是正好体现了其优点吗?
因为我们还没有实现任何东西,我们之前得到了必要的反馈。这样,我们便可以重新调整文档,并让它这次符合预期了。
现在,让我们假设已经这样做了,并且新文档已准备就绪并获得批准,因此我们刚刚完成了文档优先方案的工作流的前两个步骤。接下来,我们将添加测试以确认规范并实现 API。
在此,请允许我介绍一个可以帮助我们完成该工作流的 Gem:Skooma。
Skooma
来认识下 Skooma! 这是一个用于根据 OpenAPI 文档验证 API 实现的 Gem。
它支持最新的 OpenAPI 3.1 和 JSON Schema 2020-12 草案,带有开箱即用的 RSpec 和 Minitest 帮助方法,最后它还有一个很酷的名字,引用自上古卷轴游戏!
Skooma 并不是唯一的选择,你可以随时跳出去并瞥见其他 Gem ,例如
committee和openapi_first.
要使用 RSpec 配置 Skooma,我们只需要指定文档路径并将 Skooma 包含在请求规范中:
1
2
3
4
5
6
7
# spec/rails_helper.rb
RSpec.configure do |config|
# ...
path_to_openapi = Rails.root.join("docs", "openapi.yml")
config.include Skooma::RSpec[path_to_openapi], type: :request
end
现在,我们即可通过 skooma_openapi_schema 帮助方法访问 OpenAPI 文档,例如,根据 OpenAPI 规范对其进行验证:
1
2
3
4
5
6
7
8
9
# spec/openapi_spec.rb
require "rails_helper"
describe "OpenAPI document", type: :request do
subject(:schema) { skooma_openapi_schema }
it { is_expected.to be_valid_document }
end
于是,我们现在就可确定自己的 OpenAPI 文档是否始终有效。但重要的是,现在可以使用这些帮助方法来校验我们的 API 端点了:
- 校验请求的 path, query, headers, 和 body
- 校验响应的 status, headers, 和 body (测试错误响应)
- 校验请求和响应(测试成功路径)
以下是使用 Skooma 的 vanilla 请求规范的完整示例(没有神奇的 DSL,只有几个帮助方法):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# spec/requests/feed_spec.rb
require "rails_helper"
describe "/animals/:animal_id/feed" do
let(:animal) { create(:animal, :unicorn) }
describe "POST" do
subject { post "/animals/#{animal.id}/feed", body:, as: :json }
let(:body) { {food: "apple", quantity: 3} }
it { is_expected.to conform_schema(200) }
context "with wrong food type" do
let(:body) { {food: "wood", quantity: 1} }
it { is_expected.to conform_schema(422) }
end
end
end
就这些了!试想一下用普通的 Ruby 手动验证所有这些属性的繁琐吧。这就是 Skooma 节省时间并使你的测试更具可读性的方式!顺便说一句,我们刚刚进入了红绿重构循环【译者注:红绿重构循环是下文的 TDD 中的重要概念】:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
Validation Result:
{"valid"=>false,
"instanceLocation"=>"",
"keywordLocation"=>"",
"absoluteKeywordLocation"=>"urn:uuid:1b4b39eb-9b93-4cc1-b6ac-32a25d9bff50#",
"errors"=>
[{"instanceLocation"=>"",
"keywordLocation"=>
"/paths/~1animals~1{animalId}~1feed/post/responses/200"/
"/content/application~1json/schema/required",
"error"=>
"The object is missing required properties"/
" [\"animalId\", \"food\", \"amount\"]"}]}
# ./spec/requests/feed_spec.rb:12:in `block (3 levels) in <top (required)>'
Skooma 与文档优先的方案一起,使 TDD 方式能够实现完美的 API,确保每个功能都按照规范工作。
全部就这些了。随之而来的是,雨水清洁大地,我们准备好在干燥的土地上安顿下来,这是一片没有糟糕文档的新大陆!
Tips and tricks
从小的地方做起。可以先只针对一个端点采用文档优先的方案。一旦你和团队熟悉它了,就可以将这种方法扩展到整个 API。
对于那些从代码优先或测试优先的方案过渡的人来说,从现有代码生成 OpenAPI 文档可以作为转向文档优先方案的坚实起点。
将 Spectral 添加到 CI/CD 管道。完成此配置后,请开始使用自定义 linter 规则来强制保护你的 API 设计。例如,你可以对特定错误响应使用规则,或者例如分页,以确保它们在整个 API 中保持一致。Spectral 文档中还提供了规则集的真实示例。你可以将这些作为参考来了解有关 Spectral 的更多信息。
阅读 JSON Schema 关键字规范以提升校验水平。例如,有一个 unevaluatedProperties 关键字可用于避免向最终用户公开内部属性:
1
2
3
type: object
unevaluatedProperties: false
properties: # ...
只需将其添加到你的 schema 中,即可确保 API 是安全的。甚至可以使用自定义 linter 规则来强制执行它。
使用文档优先的方案来实现协作和早期反馈。协作是成功开发的关键,减少了代码实现过程中不必要的迭代,并实现了多功能团队的并行工作。
使用 OpenAPI 编写规范,这样你和团队就可以说同一种语言。使用 OpenAPI 生态系统中的 linter 和工具来改进文档。
最后,使用 Skooma 根据 OpenAPI 文档来测试你的应用,节省了时间和精力,使你的代码和测试更具可读性,API 更加稳定。
我希望你喜欢这种方案,你现在也可以宣布:
“要有文档”……文档就被我们创造出来了!